



Nguyên tắc tối thiểu hóa rủi ro thực nghiệm (4) – Ước lượng kì vọng Rademacher, chiều VC
Posted by Trần Quốc Long trên Tháng Bảy 7, 2009
Bài trước cho thấy mối quan hệ giữa 



Định lý: Nếu 


ta có 
Chứng minh: Theo định nghĩa
![\displaystyle \mathcal{R}_n(L_{\mathcal{F}}) = E_{X,Y,\epsilon}\left[\sup_{f \in \mathcal{F}}\frac{1}{n}\sum_{i=1}^n \epsilon_i\frac{1-Y_if(X_i)}{2} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BR%7D_n%28L_%7B%5Cmathcal%7BF%7D%7D%29+%3D+E_%7BX%2CY%2C%5Cepsilon%7D%5Cleft%5B%5Csup_%7Bf+%5Cin+%5Cmathcal%7BF%7D%7D%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_i%5Cfrac%7B1-Y_if%28X_i%29%7D%7B2%7D+%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\displaystyle =\frac{1}{2} E_{X,Y,\epsilon}\left[\sup_{f \in \mathcal{F}}\frac{1}{n}\sum_{i=1}^n (\epsilon_i Y_i) f(X_i)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D%5Cfrac%7B1%7D%7B2%7D+E_%7BX%2CY%2C%5Cepsilon%7D%5Cleft%5B%5Csup_%7Bf+%5Cin+%5Cmathcal%7BF%7D%7D%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%28%5Cepsilon_i+Y_i%29+f%28X_i%29%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\displaystyle E[\epsilon_i] = 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5B%5Cepsilon_i%5D+%3D+0&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\displaystyle = \frac{1}{2} E_{X,\epsilon}\left[\sup_{f \in \mathcal{F}}\frac{1}{n}\sum_{i=1}^n \epsilon_i f(X_i)\right] = \frac{1}{2}\mathcal{R}_n(\mathcal{F})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cfrac%7B1%7D%7B2%7D+E_%7BX%2C%5Cepsilon%7D%5Cleft%5B%5Csup_%7Bf+%5Cin+%5Cmathcal%7BF%7D%7D%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_i++f%28X_i%29%5Cright%5D+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cmathcal%7BR%7D_n%28%5Cmathcal%7BF%7D%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)


Nhận xét: Định lý cho phép liên hệ giữa kì vọng Rademacher của lớp hàm 
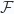
Nếu đặt 


tức là đại lượng này không phụ thuộc vào số lượng hàm trong 
Để ước lượng 
Bổ đề lớp hữu hạn Massart (Massart’s finite class lemma): Cho 

![\displaystyle E_\epsilon\left[\sup_{a\in \mathcal{A}}\frac{1}{n}\sum_{i=1}^n\epsilon_i a_i \right]\leq \frac{r\sqrt{2\log |\mathcal{A}|}}{n}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E_%5Cepsilon%5Cleft%5B%5Csup_%7Ba%5Cin+%5Cmathcal%7BA%7D%7D%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En%5Cepsilon_i+a_i+%5Cright%5D%5Cleq+%5Cfrac%7Br%5Csqrt%7B2%5Clog+%7C%5Cmathcal%7BA%7D%7C%7D%7D%7Bn%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
trong đó 
Chứng minh: Xét đại lượng ![\displaystyle R = E_\epsilon\left[\sup_{a\in \mathcal{A}}\sum_{i=1}^n\epsilon_i a_i \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R+%3D+E_%5Cepsilon%5Cleft%5B%5Csup_%7Ba%5Cin+%5Cmathcal%7BA%7D%7D%5Csum_%7Bi%3D1%7D%5En%5Cepsilon_i+a_i+%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

![\displaystyle e^{s R}\leq E_\epsilon\left[\exp \left(\sup_{a\in \mathcal{A}}s\sum_{i=1}^n\epsilon_i a_i\right) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+e%5E%7Bs+R%7D%5Cleq+E_%5Cepsilon%5Cleft%5B%5Cexp+%5Cleft%28%5Csup_%7Ba%5Cin+%5Cmathcal%7BA%7D%7Ds%5Csum_%7Bi%3D1%7D%5En%5Cepsilon_i+a_i%5Cright%29+%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

![\displaystyle = E_\epsilon\left[\sup_{a\in \mathcal{A}}\exp \left(s\sum_{i=1}^n\epsilon_i a_i\right) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+E_%5Cepsilon%5Cleft%5B%5Csup_%7Ba%5Cin+%5Cmathcal%7BA%7D%7D%5Cexp+%5Cleft%28s%5Csum_%7Bi%3D1%7D%5En%5Cepsilon_i+a_i%5Cright%29+%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\displaystyle \leq E_\epsilon\left[\sum_{a\in \mathcal{A}}\exp \left(s\sum_{i=1}^n\epsilon_i a_i\right) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleq+E_%5Cepsilon%5Cleft%5B%5Csum_%7Ba%5Cin+%5Cmathcal%7BA%7D%7D%5Cexp+%5Cleft%28s%5Csum_%7Bi%3D1%7D%5En%5Cepsilon_i+a_i%5Cright%29+%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

![\displaystyle = \sum_{a\in \mathcal{A}}E_\epsilon\left[\exp \left(s\sum_{i=1}^n\epsilon_i a_i\right) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Csum_%7Ba%5Cin+%5Cmathcal%7BA%7D%7DE_%5Cepsilon%5Cleft%5B%5Cexp+%5Cleft%28s%5Csum_%7Bi%3D1%7D%5En%5Cepsilon_i+a_i%5Cright%29+%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\displaystyle E[X+Y]=E[X]+E[Y]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E%5BX%2BY%5D%3DE%5BX%5D%2BE%5BY%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\displaystyle = \sum_{a\in \mathcal{A}} \prod_{i=1}^n E_{\epsilon_i}\left[e^{s\epsilon_i a_i}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Csum_%7Ba%5Cin+%5Cmathcal%7BA%7D%7D+%5Cprod_%7Bi%3D1%7D%5En+E_%7B%5Cepsilon_i%7D%5Cleft%5Be%5E%7Bs%5Cepsilon_i+a_i%7D%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)






Lấy loga cả hai vế ta được 



Bổ đề Massart giúp ta ước lượng
Định lý: Với lớp hàm phân lớp 


Chứng minh: Ta có
![\displaystyle \mathcal{R}_n(\mathcal{F}) = E_{X,\epsilon}\left[\sup_{f \in \mathcal{F}}\frac{1}{n}\sum_{i=1}^n \epsilon_i f(X_i)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BR%7D_n%28%5Cmathcal%7BF%7D%29+%3D+E_%7BX%2C%5Cepsilon%7D%5Cleft%5B%5Csup_%7Bf+%5Cin+%5Cmathcal%7BF%7D%7D%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_i+f%28X_i%29%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\displaystyle = E_X\left[E_\epsilon\left[\left.\sup_{f \in \mathcal{F}}\frac{1}{n}\sum_{i=1}^n \epsilon_i f(X_i)\right|X\right]\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+E_X%5Cleft%5BE_%5Cepsilon%5Cleft%5B%5Cleft.%5Csup_%7Bf+%5Cin+%5Cmathcal%7BF%7D%7D%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_i+f%28X_i%29%5Cright%7CX%5Cright%5D%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\displaystyle \leq E_X\left[\frac{r_X\sqrt{2\log|\Pi_{\mathcal{F}}(X)|}}{n}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleq+E_X%5Cleft%5B%5Cfrac%7Br_X%5Csqrt%7B2%5Clog%7C%5CPi_%7B%5Cmathcal%7BF%7D%7D%28X%29%7C%7D%7D%7Bn%7D%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\displaystyle \leq E_X\left[\sqrt{\frac{2\log G_{\mathcal{F}}(n)}{n}}\right] = \sqrt{\frac{2\log G_{\mathcal{F}}(n)}{n}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleq+E_X%5Cleft%5B%5Csqrt%7B%5Cfrac%7B2%5Clog+G_%7B%5Cmathcal%7BF%7D%7D%28n%29%7D%7Bn%7D%7D%5Cright%5D+%3D+%5Csqrt%7B%5Cfrac%7B2%5Clog+G_%7B%5Cmathcal%7BF%7D%7D%28n%29%7D%7Bn%7D%7D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

Hệ quả: Nếu chiều VC của lớp hàm 

Chứng minh: Thật vậy, nếu chiều VC của lớp hàm 


Nhận xét: Kết quả này chứng tỏ
- Nguyên tắc tối thiểu hóa rủi ro thực nghiệm khả thi vì
với xác suất cao khi số mẫu học
nghĩa là rủi ro kì vọng của
xấp xỉ rủi ro kì vọng thấp nhất có thể được với xác suất cao.
- Ước lượng
- Tại sao phải cẩn trọng khi áp dụng nguyên tắc tối thiểu hóa rủi ro thực nghiệm (ERM) khi chiều VC vô hạn hoặc rất lớn ? Bởi vì khi một lớp hàm
mà ta muốn (mặc dù rủi ro thực nghiệm (số lỗi) trên tập mẫu học bằng 0). Đây chính là hiện tượng học quá (overfitting) khi sử dụng các lớp hàm có khả năng biểu diễn mạnh (ví dụ: mạng nơron – neural network).


Bình luận về bài viết này